Modernizacija IT infrastrukture velike kompanije podrazumeva značajan redizajn postojećeg informacionog sistema…
Cilj ovog projekta bio je formiranje informacionog sistema koji bi obezbedio platformu za pokretanje svih servisa kritičnih za proizvodnju i usklađivanje kontrolnih servisa sa normativima propisanim od strane EU radi strože kontrole proizvodnje i prodaje. Informacioni sistem su pre realizacije ovog projekta činila tri nezavisna data centra. Jedan od centara pokretao je više od 90% relevantnih servisa, dok je data centar na lokaciji u Beogradu služio kao DR lokacija za produkcione servise iz glavnog centra. Za obezbeđenje podataka na DR lokaciji korišćena je vSphere replikacija sa jednom dnevnom kopijom (24 h RPO). Veeam Backup and Replication korišćen je kao osnovni alat za bekap virtuelne infrastrukture.
Tehnički zahtevi
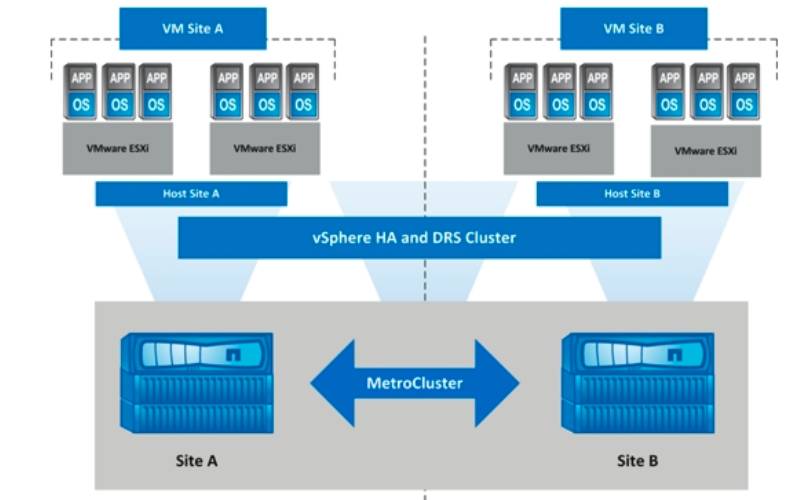
Primarni cilj bio je formiranje informacionog sistema tolerantnog na ispade, tj. na otkazivanje čitavog data centra, sa zahtevom da servisi, ukoliko i dođe do otkazivanja jednog od data centara, moraju da započnu sa radom na drugom bez ikakvog gubitka podataka i sa što većim stepenom automatizacije. To je podrazumevalo značajan redizajn informacionog sistema kod korisnika: pored serverske i storidž infrastrukture, trebalo je redizajnirati i celokupnu mrežnu infrastrukturu, s obzirom da je sistem do tada bio centralizovan.
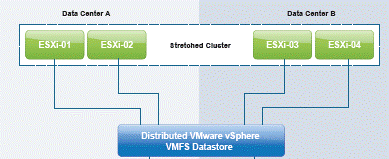
Infrastrukturno rešenje koje je zadovoljavalo zahteve korisnika baziralo se na formiranju uniformnog metro klaster sistema, zasnovanog na VMware platformi i sertifikovanom hardveru za kreiranje virtuelne infrastrukture. Metro klaster rešenja, koja se ponekad nazivaju i stretched klaster rešenjima, predstavljaju formiranje klastera virtuelne infrastrukture na dve međusobno udaljene fizičke lokacije identične organizacije, koristeći ekvivalentne mehanizme za sinhronu replikaciju podataka na storidž sistemima koji čine klaster. Udaljenost između lokacija treba da zadovolji potrebe korisnika, ali je istovremeno ograničena izborom vendora i konkretnog rešenja, odnosno konfiguracije. Osnovna karakteristika uniformnog metro klaster rešenja je da fizički serveri imaju pristup do storidž sistema na obe lokacije. Na ovaj način postiže se veća fleksibilnost, a u konkretnom slučaju ovakva organizacija bila je obavezna, zbog implementacije Microsoft Failover klastera za potrebe servisa. Obe lokacije su ekvivalentno organizovane u pogledu opreme, klimatizacije, zaštite i mrežne konfiguracije. Prethodno centralizovana mreža reorganizovana je tako da su obe lokacije postale autonomne, sa višestrukim kroskonekcijama između lokacija, realizovanim po različitim trasama.
Servisi

Servisi neophodni za usaglašavanje sa EU direktivama imaju sloj za bazu podataka baziran na Microsoft SQL serveru, aplikativni sloj na kome su instalirani potrebni servisi i web sloj. Pored mehanizama visoke dostupnosti na nivou infrastrukture, ovi servisi su dodatno unapređeni uvođenjem klastering mehanizama na nivou samih instanci – tu su Microsoft Failover klaster za potrebe baze podataka i aplikativnih servisa i NLB za potrebe web servisa. Ovi zahtevi doneli su niz dodatnih sistemskih ograničenja pri zadovoljavanju generalnih planova za DR i standardizovanih bekap procedura, usvojenih u lokalnoj kancelariji (svaki podatak bekapuje se na dva mesta, sa sedam tačaka oporavka i udaljenom replikom na beogradskoj lokaciji).
Primena Microsoft Failover klastera donela je i prednosti: omogućeno je postavljanje aktivnih i standby nodova, DB, app i web servisa na različite fizičke lokacije i različite kontrolere storidž sistema, čime je omogućeno funkcionisanje servisa bez prekida u radu u slučaju problema na nekoj od lokacija. Dodatno, servisi se mogu prebacivati sa aktivnog na standby nod bez praznog hoda (downtime), čime je eliminisana potreba za prekidom u radu tokom standardnog održavanja. Microsoft Failover klaster za potrebe DB i app servisa realizovan je na virtuelnim mašinama, korišćenjem RDM diskova (physical mode). Generalno, virtuelne mašine sa RDM diskovima imaju niz ograničenja, pa na njima nije bio moguć dotad standardni način za DR (vSphere replikacija) i bekap (Veeam bekap virtuelnih mašina). Jedini način da se nastavi sa korišćenjem DR zaštite bio je da se storidž sistemi nadograde licencama za storidž replikaciju (SnapMirror), čime je omogućena replikacija sadržaja i ovih virtuelnih mašina.
Problem sa nemogućnošću bekapovanja virtuelnih mašina sa pRDM diskovima prevaziđen je korišćenjem Veeam agenta za Windows, koji je u potpunosti podržan za bekap nodova Microsoft Failover klastera. Veeam Agent for Windows je relativno svež alat, namenjen prvenstveno bekapu fizičkih servera, ali je u ovom slučaju, zbog pRDM diskova, implementiran na virtuelnim mašinama. Ostatak mašina je bekapovan na standardni način, kroz Veeam Backup and Replication. Implementirano rešenje Uniformni VMware metro klaster implementiran je na dve lokacije, međusobno udaljene nekoliko stotina metara. Za storidž sisteme na ovim lokacijama odabrano je NetApp metro klaster rešenje. Rastojanje između lokacija iznosi nekoliko stotina metara, pa je odabrana stretched varijanta i sistemi bazirani na FAS8200 kontrolerima. Serverska infrastruktura unapređena je nabavkom novih servera, tako da su svi VMware hostovi bazirani na poslednjoj generaciji HPE servera (gen10) i SkyLake procesorskoj arhitekturi. Dekomisionirani hardver, koji čine nešto stariji serveri (gen9) i NetApp FAS2650 storidž sistem, sa dodatnim policama koje su iskorišćene za smeštanje replika sa produkcionih lokacija, prebačen je na rezervnu lokaciju. Posebna pažnja tokom implementacije ovog rešenja posvećena je obezbeđenju integriteta podataka i unapređenju pouzdanosti. Pojedini mehanizmi bili su od ključnog značaja za postizanje ovih ciljeva:
Za najvažnije servise napravljeni su Failover klasteri na nivou Windows instanci, gde su nodovi raspoređeni na različitim fizičkim lokacijama.
Automatski oporavak ostalih servisa na klasteru virtuelne infrastrukture omogućen je ugrađenim HA mehanizmima.
Storidž sistemi na lokacijama metro klaster sistema su u sinhronoj sprezi.
Postoji alternativna lokacija za DR, udaljena više stotina kilometara, na koju se podaci kopiraju sa jednočasovnom zadrškom (1 h RPO).
DR mehanizam oporavka omogućen je korišćenjem VMware Site Recovery Manager-a.
Veeam je primarni alat za bekap virtuelne infrastrukture i Microsoft Failover klastera.
Primenjena je Veeam-ova preporuka o pravljenju višestrukih kopija bekapa i korišćenju cold medijuma (trake).
Uopšteno posmatrano, servisi koji su važni za proces proizvodnje imaju drugačiji tretman u odnosu na ostale i za njih je potrebno maksimizirati raspoloživost, odnosno svesti verovatnoću otkazivanja na minimum i eliminisati mogućnost gubitka i korupcije podataka. Ovi zahtevi su prisutni kada određeni servisi participiraju u proizvodnom procesu, jer se tada downtime ovih servisa može relativno jednostavno iskazati u finansijskom kontekstu. Ova implementacija je primer jednog takvog rešenja infrastrukturnih problema za sistem od velikog uticaja na proizvodne cikluse. Ključni elementi koji su definisali izgled sistema jesu redundansa na logičkom nivou, višestruke kopije podataka unutar sistema, autonomija data centara u mrežnom kontekstu i arhive podataka.

Aleksandar Pavlović





0 %s Comments